"빅데이터에서의 R활용" 강의 중 통계학 강의를 할 때 먼저 설명하는 통계분석기법이 "카이제곱검정"과 "t 검정" 입니다.
"카이제곱검정"은 조사설문지 등을 분석할 때 90% 이상 사용되는 통계분석기법이고,
"t검정"은 분석기법 중에 가장 설명하기 쉬운 기법이기 때문입니다.
"t 검정"은 간단하게 "남녀별 평균키의 차이가 있는가?"를 분석하는 기법이고
"카이제곱검정"은 간단하게 "남녀별 취미생활에 차이가 있는가"를 분석하는 기법입니다.
기초통계학 시간에는 "정규분포"를 배우고 나면 곧바로 "t 분포"를 배우게 되는데,
이 t 분포를 따르는 변수를 분석하는 것이 t 검정입니다.
(1) t 분포의 역사
이렇게 간단한 't분포', 't 검정'은 't' 라는 단어때문에 처음 통계학을 공부하는 사람들에게는 많은 부담이 됩니다.
1900년대 초반에 '고셋"이라는 사람이 't분포'를 발표할 때에는 그 당시에는 어려운 통계 분포였을지도 모릅니다.
그냥 간단하게 "두 그룹간에 차이가 있는가?" 예를 들어 남녀별 급여차이가 있는가?
결혼유무에 따른 TV 시청시간 차이가 있는가? 하는 것을 분석하는 기법이 "t검정"입니다.
이렇게 간단한 기법에 대하여 t 분포의 역사적 배경을 살펴보는 것도 t 분포를 이해하는데 도움이 됩니다.
고셋(William Sealy Gosset, 1876~1937)은 옥스퍼드 대학에서 수학과 화학을 전공했습니다.
* 칼 피어슨, 로널드 피셔와 거의 같은 시대에 살았습니다.(모두 영국)
고셋은 아일랜드 맥주회사인 기네스 양조장에서 근무하게 됩니다. 고셋은 맥주맛이 일정하지 않은데
불만을 가지게 됩니다. 맥주맛을 결정하는효모를 분석하여 맥주맛이 일정하도록 효모의 양을 연구하게 됩니다.
표본수가 작기 때문에 정규분포를 적용하기에는 어려움이 있었는데, 정규분포랑 비슷하면서
자유도 개념을 추가한 t분포를 만들게(?) 발견하게(?) 됩니다.
그런데 회사에서는 회사의 기밀에 해당하는 이유로 발표를 못하게 하였습니다.
고셋은 자기의 실명을 사용하지 않고 Student(학생) 라는 이름으로 논문을 발표합니다.
세상을 떠난 뒤 그를 기념하기 위해 준비하는 중, Student가 고셋이라는 사실을 알고
세상에 알려지게 됩니다.
참고문헌:
위키백과 스튜던트 t 분포
데이터를 부탁해(한빛미디어, 전약진 지음)
수학자들의 주사위"(뿌리와 이파리, 데이비드 실스버그 지음, 최정규옮김)
(2) t 검정이란?
t-검정은 두 집단간의 (평균치) 차이를 분석하고자 하는 경우 사용하는 기법입니다.
예를 들면 "남녀별 급여의 차이가 있는가?"를 분석하고자 할 때 사용되는 기법입니다.
그러면 "세 집단 이상의 평균치차이 검정의 경우에는 어떻게 분석할까?"라는 의문이 생길 것입니다.
이는 다음에 설명하는 분산분석법(ANOVA)을 이용하면 됩니다.
다음은 두 학급에서 뽑은 학생 6명의 국어성적입니다.
학급 1 학급2 학급3
60 64 83
66 69 76
72 75 82
78 81 97
84 87 98
80 92 99
두 학급의 국어 성적의 평균값의 차이를 비교하는 프로그램은 다음과 같습니다.
| /*-------------------------------------------*/ /* t-검정의 간단한 형태 -SAS */ /*-------------------------------------------*/ 1 DATA a1;INPUT group score @@; 2 CARDS; 3 1 60 2 64 4 1 66 2 69 5 1 72 2 75 6 1 78 2 81 7 1 84 2 87 8 1 80 2 92 9 ; 10 PROC TTEST;CLASS group;VAR score; 11 RUN; |
[설명]
10 PROC TTEST;CLASS group;VAR score;
t-검정에 사용되는 PROC TTEST는 두 부분으로 구성됩니다.
CLASS 문은 그룹구분, 즉 독립변수인 학급의 구분을 나타내며,
VAR 문은 분석하고자 하는 변수, 즉 종속변수를 나타내는데 여기서는 국어성적을 나타냅니다.
그 결과는 다음과 같습니다.
결과 10 PROC TTEST;CLASS group;VAR score;의 결과
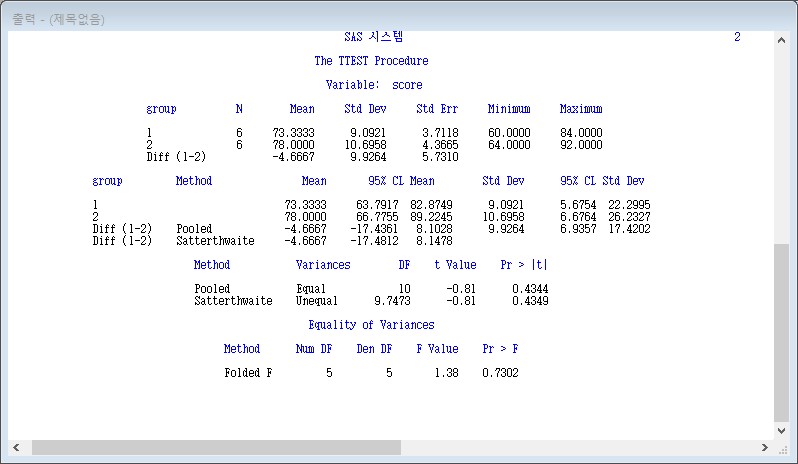
두 학급의 국어 성적의 평균은 73.333, 78.000이며 통계적으로 차이가 있다고 말할 수 없습니다.
(Prob>|T|가 0.4344이므로)
그러므로 "두 학급의 국어성적 평균치 차이는 없다." 즉 "두 학급의 국어 성적은 차이가 없다"라는 결론을 내립니다.
그런데 두 학급의 국어 성적은 자세히 살펴보면 분명히 다릅니다.
이와 같이 실제 자료에는 차이가 있는데 왜 "차이가 없습니다."라고 결정을 내릴까?
이는 두 집단의 차이는 각각의 집단을 대표할 수 있는 "대표값"의 차이로 해석하여
이 대표값이 서로 차이가 없으면 두 집단이 차이가 없는 것으로 결론을 내리기 때문입니다.
대표값으로는 보통 산술평균을 많이 사용합니다.
(2-2) t검정 R 예제
| x1 <- c(60,66,72,78,84,80) x2 <- c(64,69,75,81,87,92) t.test(x1,x2) t.test(x1,x2,var.equal=T) # 분산이 같은 경우 var.test(x1,x2) |
R에서는 {stats} 패키지에 들어 있는 t.test( ) 함수를 이용합니다.
아시겠지만 t검정 이전에 먼저 분산이 같은가?를 먼저 검정하시고(var.test)
분산이 같은 경우 var.equal=TRUE 라는 옵션을 사용해야 합니다.
var.equal=T 를 생략하면 기본적으로(default)로 분산이 다른 경우로
간주하고 결과가 나오니 각별히 주의하셔야 합니다.
'SAS강좌와 통계컨설팅 - 통계편 > 20. t 검정' 카테고리의 다른 글
| (P)제18강(01)_t 검정(파이썬) - ttest_ind() : SAS, R 비교 (0) | 2021.12.18 |
|---|