* "최대우도함수" "Maximum Likelihood Estimator"를 보다가 "likelihood"가 어디에 사용되는가? 에 대한 예제를 준비하다가 머신러닝의 한 기법인 "나이브베이즈("naivBayes")를 사례로 들면 되겠다는 생각에 정리해 보았습니다.
여기서는 iris 데이터의 경우를 예로 들었지만, 범주형데이터인 경우인 스팸메일인 경우 또는 Titanic 데이터를 정리하여 추후에 올릴려고 합니다.
베이지안은 과거의 이미 일어난 어떤 사건의 “사전확률”“사전 확률”을 알고 있을 때,
앞으로 어떤 사건이 일어날 확률(사후 확률)을(사후확률) 결정하는 이론입니다.
기초통계학에 나오는 베이즈 추론의 식은 다음과 같습니다.

P(A|B)는 사건 B가 일어났을 때 사건 AA 가 일어날 조건부 확률을 말합니다.
그리고 사건 A와 B가 동시에 일어날 확률은 사건 A가 일어날 확률 P(A)과 조건부 확률 P(B|A)을 곱한 값이 됩니다.
나이브베이즈는 이 공식을 이용하게 되는데 변수가 많아지면 이 식들을 계산하기 쉽지가 않게 됩니다.
사용하는 패키지는 e1071 입니다.
|
> library(e1071) |
e1071에
나이브베이즈를 실행할 수 있는 naiveBayes( )함수도 있고,
SVM을 실행할 수 있는 svm( )함수도 있습니다.
데이터 iris를 이용하여 간단하게 naiveBayes를 실행하는 프로그램을 실었습니다.
우리에게 익숙한 데이터 iris를 사용하여 naivaBayes를 쉽게 실습할 수 있는 것을 보이기 위함입니다.
|
> library(e1071) # Naive Bayes 모델을 활용하기 위한 ’e1071’패키지 설치 > naiveBayes(Species ~ ., data=train) # 분류모델 생성 # 데이터 train 을 이용하고, 모형 생성 > model_nai <- naiveBayes(Species ~ ., data=train) # 분류모델 생성 # 모형을 객체 생성 > model_nai <- naiveBayes(train[-5], train$Species) # #model # 105개 학습 데이터를 이용하여 x변수(4개)를 y변수로 학습시킴 > model_nai |
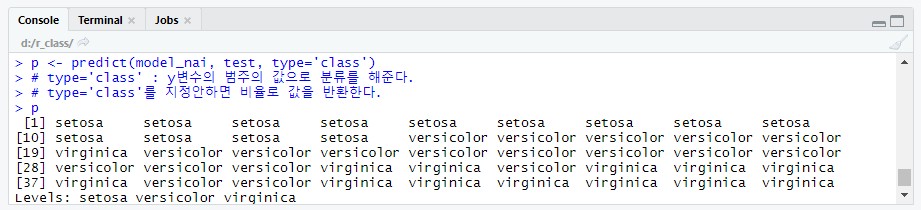
| #--- (7.3) 분류모델 평가 : test data 이용 # (형식) predict(model, test, type='class') p <- predict(model_nai, test, type='class') # type='class' : y변수의 범주의 값으로 분류를 해준다. # type='class'를 지정안하면 비율로 값을 반환한다. p |
#--- (7.4) 분류모델 평가(예측결과 평가) - 분류 정확도
t <- table(p, test$Species) # 예측결과, 원형 test의 y변수
t
#--- (7.5) 분류 정확도
(t[1,1]+t[2,2]+t[3,3])/nrow(test)

* 나이브베이즈의 예제로 적당한 것으로는 "스팸메일" 예측이 있습니다.
참고문헌으로는 R을 활용한 기계학습(에이콘, 4장 확률론적 학습: 나이브베이즈를 사용한 분류"를
보시면 참고가 될 것입니다.
|
(저의 생각) . |