[SAS]
DATA a1;INPUT group score @@; * 3학급의 국어 성적;
CARDS;
1 60 2 64 3 83
1 63 2 69 3 77
1 72 2 75 3 82
1 78 2 81 3 97
1 84 2 87 3 99
1 79 2 92 3 89
;
DATA a1;SET a1;
IF group IN (1,2); * 그룹 1,2 를 추출, t검정은 두 그룹간 평균치 차이 검정이니까;
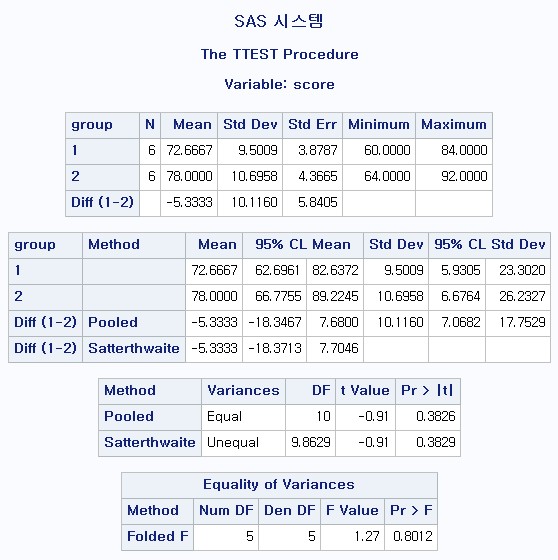
PROC TTEST;CLASS group;VAR score; * CLASS 에는 독립변수 group 지정, VAR 에는 종속변수 score 지정;
RUN;
[R]
주의할점:
t검정을 하려면 t.test( ) 함수를 사용하면 됩니다.
그런데 무작정 t.test( ) 를 사용하면 안 됩니다. 이는 기본(default)으로 "두 그룹의 분산이 다른 경우"에
사용합니다.
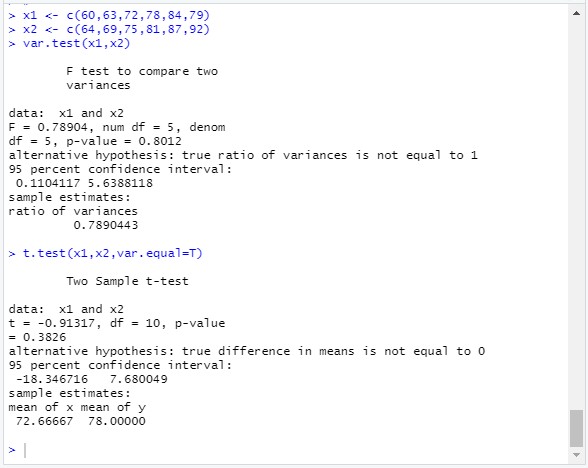
그리하여 먼저 두 집단의 분산이 같은지? var.test( )를 통하여 검정을 먼저 해야 합니다.
두 집단의 분산이 같은 경우에는 var.equal=T옵션을 사용해야 합니다.
x1 <- c(60,63,72,78,84,79) # 3학급의 국어 성적을 벡터로 입력
x2 <- c(64,69,75,81,87,92)
x3 <- c(83,77,82,97,99,89)
var.test(x1,x2) # 학급1과 학급2의 분산을 먼저 검정
t.test(x1,x2,var.equal=T) # 분산이 같으므로 var.equal=T 라는 옵션을 지정 *주의
[Python]
Python 을 이용한 t 검정은 여러 방법이 있으나 Scipy라이브러리를 이용했습니다.
# 귀무가설 : 두 그룹간의 평균치 차이가 같다.
# 대립가설 : 두 그룹간의 평균치 차이기 다르다.
from scipy import stats
x=[60,63,72,78,84,79]
y=[64,69,75,81,87,92]
z=[83,77,82,97,99,89]
result1 = stats.ttest_ind(x, y)
result2 = stats.ttest_ind(x, y, equal_var=True)
result3 = stats.ttest_ind(x, y, equal_var=False)
print("t검정 통계량: %.3f, pvalue=%.3f"%(result1))
print("t검정 통계량: %.3f, pvalue=%.3f"%(result2))
print("t검정 통계량: %.3f, pvalue=%.3f"%(result3))

'R & SAS 300제' 카테고리의 다른 글
| 회귀분석 - SAS, R, Python 이용 (0) | 2021.11.20 |
|---|---|
| 상관분석 - SAS, R, Python (0) | 2021.11.20 |
| 행과 열의 합계 구하기 - apply계열(sapply, lapply, tapply), aggregate (0) | 2021.11.17 |
| 표본추출하기 - sample 함수 (0) | 2021.11.17 |
| 데이터를 정렬하기 - SAS, R - sort, order, decreasing (0) | 2021.11.16 |