===============================================
수많은 단어들 중에 헷갈리는 단어들이 있습니다.
표준화(standardize)와 정규화(normalize),
릿지 regression(능형회귀분석)과 라소(Lasso) 회귀분석 등
================================================
표준화와 정규화 단어 중에서 먼저 표준화만 알면 됩니다...
표준이니까 우선 영어로 standard, 표준화는 standardise
표준이니까 일단 평균을 빼고, 표준편차로 나누는 것..
$$z= \frac{x- \bar{X}} {\sigma }$$
[SAS]
DATA a1;
INPUT gender $ wei hei age;
CARDS;
F 65 171 23
F 66 172 24
F 69 176 38
M 67 173 43
M 68 177 40
M 72 178 42
;
PROC PRINT; RUN; * 데이터 확인
PROC STANDARD M=0 STD=1 OUT=out1; * 평균이 0, 표준편차 1인 표준화
RUN;
PROC PRINT;RUN; * 표준화 데이터 확인
PROC MEANS DATA=out1 MAXDEC=2; * 표준화된 데이터를 평균과 표준편차 구하기, 당연히 평균 0, 표준편차 1
RUN;
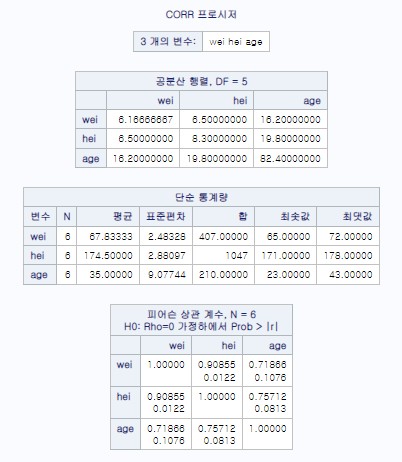
PROC CORR DATA=a1 COV;VAR wei hei age; * 원래 표준화 하기전 공분산과 상관계수 구하기;
RUN;
PROC CORR DATA=out1 COV;VAR wei hei age; * 표준화된 이후의 데이터의 공분산은 원래 데이터의 상관계수와 같다
RUN;

[R]
#* (1.1) 표준화 ----
wei <- c( 65, 66, 69, 67, 68, 72)
hei <- c(171,172,176,173,177,178)
age <- c(23,24,38,43,40,42)
a1 <- data.frame(wei,hei,age)
scale(a1,center = TRUE,scale=TRUE)
# center = TRUE,scale=TRUE: 평균 빼고, 표준편차로 나눔
# scale(a1,center = FALSE,scale=TRUE)
#* (1.2) 정규화 ----
age_nor <- (age-min(x)) /(max(age)-min(age))
age_nor

[정규화]
* 이제 정규화를 생각해 보자.
(원래값 - 최소값) / (최대값-최고값)
정규화를 하면 범위가 0~1 사이가 되겠구나....
"정규화" 영어로 하면 normalize 여기까지...
정규분포가 normal 분포... 생각도 말자 제발 정규분포랑 연관되어 생각 말자
다시 표준화만 생각하지
'R & SAS 300제' 카테고리의 다른 글
| 비모수(non-parametric) 검정 - SAS, R, SPSS 비교 (0) | 2021.11.25 |
|---|---|
| 단계적 회귀분석(mtcars 이용)-SAS, R 이용하기 (0) | 2021.11.21 |
| 회귀분석 - SAS, R, Python 이용 (0) | 2021.11.20 |
| 상관분석 - SAS, R, Python (0) | 2021.11.20 |
| t검정-두 그룹간의 평균치 차이 검정 - SAS, R, Python (0) | 2021.11.18 |



