텍스트마이닝 관련하여 정리해 두었던 다시 정리를 해 봅니다.
텍스트마이닝에 많이 사용되는 패키지로는 영어 tm, 한글 KoNLP 가 있습니다.
우선 tm 패키지 사용법을 정리해 봅니다.
자료로는 인터넷을 통해 미국독립선언서를 구하여 사용했습니다.
* 미독립선언서의 일부이긴 하지만 공유해도 되는 건지 잘 모르지만, 암튼 올려 봅니다.
이와 관련 문제가 있으면 저에게 알려 주시면 많은 도움이 되겠습니다.
# 독립선언서(영어)
1단계. 독립선언서(영어)를 읽어 들입니다.
indep <- readLines("d:/r_class/indep(eng)_02.txt") # Readlines 로 들어들입니다.
class(indep) # character # class가 "character" 인 것을 보면 "벡터"인 것을 알 수 있습니다.
length(indep) # 13 인 것으로 보다 독립선언서의 일부자료가 13문장인 것을 확인
indep[1] # 벡터의 1번째 문장을 확인할 수 있습니다.
2단계. 패키지 wordcloud와 패키지 tm 을 설치합니다.
install.packages("wordcloud") # wordcloud를 설치합니다.
library(wordcloud)
#필요한 패키지를 로딩중입니다: RColorBrewer
install.packages("tm") # wordcloud를 실행하면 먼저 tm 을 설치하라는 메세지가 나타남
# package ‘NLP’ successfully unpacked and MD5 sums checked
# package ‘slam’ successfully unpacked and MD5 sums checked
# package ‘tm’ successfully unpacked and MD5 sums checked
library(tm)
# 필요한 패키지를 로딩중입니다: NLP
3단계. wordcloud 를 실행해 봅니다.
wordcloud(indep,random.order=T) # 워드클라우드가 멋있게 나타납니다.

wordcloud(indep,min.freq = 1,random.order=T) # 1번이상
min.freq=1 옵션을 사용하니까 한 번이라도 들어 있는 단어들이 전부 나타나는 것을 볼 수 있습니다.

4단계 말뭉치(Corpus) 만들기
패키지 tm의 함수 Corpus() 를 이용합니다. VectorSource 를 이용하여 벡터에서 변환한 한 후에
Corpus 함수를 적용합니다.
> library(tm)
#----- 말뭉치(corpus) 만들기
> crude <- Corpus(VectorSource(indep)) # VectorSource 를 이용하여 벡터에서 변환
5단계. 말뭉치 살펴보기 - 여기서 좀 헷갈림
> crude # 말뭉치 객체인 "crude" 을 보려고 >crude 를 치면 메타정보만 나오고 내용을 볼 수 없습니다.
> class(crude) # [1] "SimpleCorpus" "Corpus" # 그래서 class 확인을 해봐도 "SimpleCorpus" "Corpus" 나옴
|
> crude <- Corpus(VectorSource(indep)) |
6단계. 말뭉치 살펴보기 - inspect( ) 함수 사용!!! 키포인트
#----- 말뭉치 확인 - inspect()
inspect(crude)

7단계. 패키지 tm 살펴보기 - help(package=tm)
help(package=tm)를 이용하여 패키지 tm 에 들어 있는 함수를 살펴보면 다음과 같습니다.
TermDocumentMatrix 란 함수
tm_map 함수
VectorSource함수
위로 옮기면 removePuctuation removeNumbers 도 보입니다.

8단계. tm_map 함수 사용하기 - 두 칸 빈칸없애기 tm_map(crude,stripWhitespace)
#----- 두 빈칸 없애고 확인 - tm_map(crude,stripWhitespace)
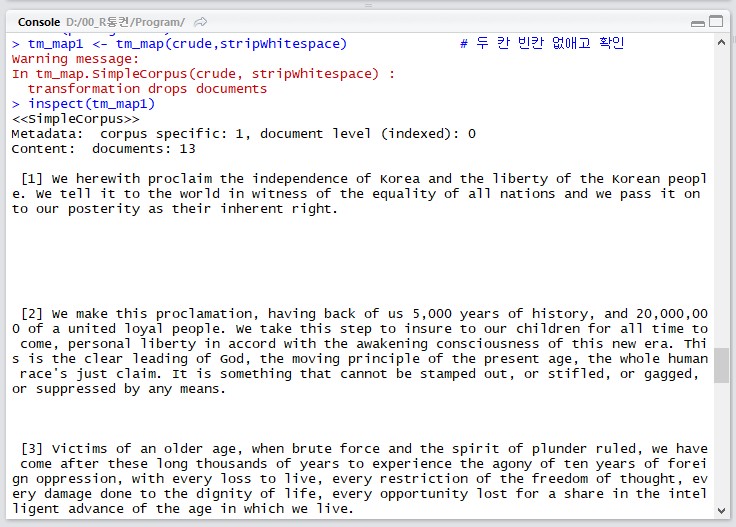
tm_map1 <- tm_map(crude,stripWhitespace) # 두 칸 빈칸 없애고 확인
inspect(tm_map1)
원래의 말뭉치와 비교하면 두개 빈칸들이 없어진 것을 볼 수 있습니다.
8단계 다음과 같은 작업들을 계속
소문자로 바꾸고... 확인
. , 없애고... 화인
숫자 없애고... 확인
특정 단어 없애... 확인
a, an, the 등 관사, 전치사, 조사, 접속사 없애고... 확인
그리고 워드클라우드 만들어 보기
|
#----- 소문자로 바꾸기 |

'R강좌와 통계컨설팅 - 통계편 > 31_00. R 응용' 카테고리의 다른 글
| (R3)제14강(3.1) 텍스트마이닝 - TDM(Term Document Matrix) (0) | 2020.12.22 |
|---|---|
| (4) 텍스트마이닝 - 문서간의 유사도(Similarity) (0) | 2020.08.01 |
| (2) 텍스트마이닝 - 말뭉치로 TermDocumentMatrix 형태로 만들기 (0) | 2020.07.30 |
| (R1)제15강(0.0) R 응용(II) 목차 - 워드클라우드, 텍스트마이닝, 장바구니, Shiny 등 (0) | 2020.07.15 |
| (R1)제15강(1.1) 워드클라우드(wordcloud) 간단하게 실행해 보기 (0) | 2020.06.03 |


