1995년에 Vapnik와 Cortes Support Vector Machine(SVM) 발표
참고서적: An Introduction to Statistical Learning with Applications in R
"SVM의 초평면을 찾는 개념은 로지스틱회귀분석과 선형판별분석과 같은 고전적인
분류기법과는 명백히 다른 것처럼 보였다... 더욱이 비선형클래스 경계를 수용하기 위해
변수공간을 확장하는 Kernel을 사용하는 개념은 독특하고 귀중한 특징처럼 여겨졌다"
"하지만 이후 SVM과 고전적인 다른 방법들 사이에 깊은 관련성이 있음이 드러났다"
(ISLR 9장에서 인용)
저도 처음에 SVM 을 보면서 심지어는 말도 안된다고 생각했습니다.
초평면
SVM 공부를 하려면 제일 먼저 초평면이란 개념을 알아야 합니다.
최대마진
그런 다음 마진이라는 것을 알아야 하고, 이 마진을 최대화하는 것이 최선의 분류기가 됩니다.
(1) SVM실습 - 패키지 e1071, 함수 svm, 옵션 kennel='radial' 디폴트옵션
우리에게 익숙한 붓꽃(iris) 데이터를 이용합니다.
install.packages("e1071") # 패키지 e1071을 설치하기
library(e1071) # 패키지 e1071 로딩하기
data(iris)
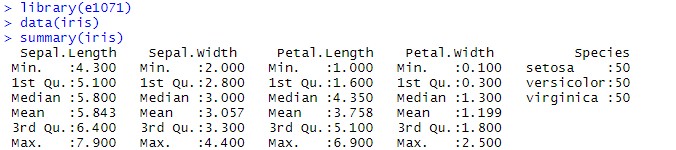
summary(iris) # 데이터 iris 의 기술 통계량
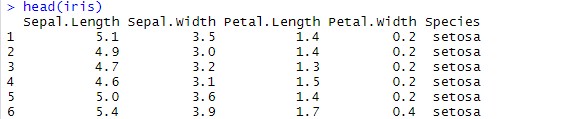
head(iris) # 데이터 iris 데이터 살펴보기
?svm
model_svm <- svm(Species~., data = iris) # 패키지 {e1071}의 svm( ) 함수를 이용, 디폴트 옵션 kernel="radial"
model_svm

pred <- predict(model_svm,iris,type="class") # SVM 적용한 모델의 예측
c.table <- table(iris$Species,pred) # 혼동 행렬(Confusion Matrix) 만듦
c.table # 실제 결과(Specise 종류)와 예측 결과와의 비교

SVM 모형 진단 - 패키지 caret, confusionMatix 함수
pred_svm <- predict(model_svm,iris)
confusionMatrix(pred_svm,iris$Species)
