이제 머신러닝 기법 중 하나인 군집분석(Cluster Analysis)에 대한 간단한 실습을 합니다.
사용되는 데이터는 유명한 붓꽃데이타 iris 이고, 패키지는 R 설치할 때 기본적으로 설치되는 {stats}입니다.
# (2.2) 군집분석 간단한 실습 -iris
# 유사성 - Distance 구하기----
# 각 row 들의 거리를 구한다...
dist(iris[1:7,1:4]) # 7개 관측치 간의 거리를 구한다...

dist01 <- round(dist(iris[1:14,1:4]),digits=3) # 소수7자리... 소수 3 자리
dist01

# Default method="euclidean"
# dist01 <- round(dist(iris[1:14,1:4],method="euclidean"),digits=3);dist01
# (2.3) 군집분석 - hclust()----
hc <- hclust(dist01, method="ave")
plot(hc)
plot(hc,hang=-1)

?hclust
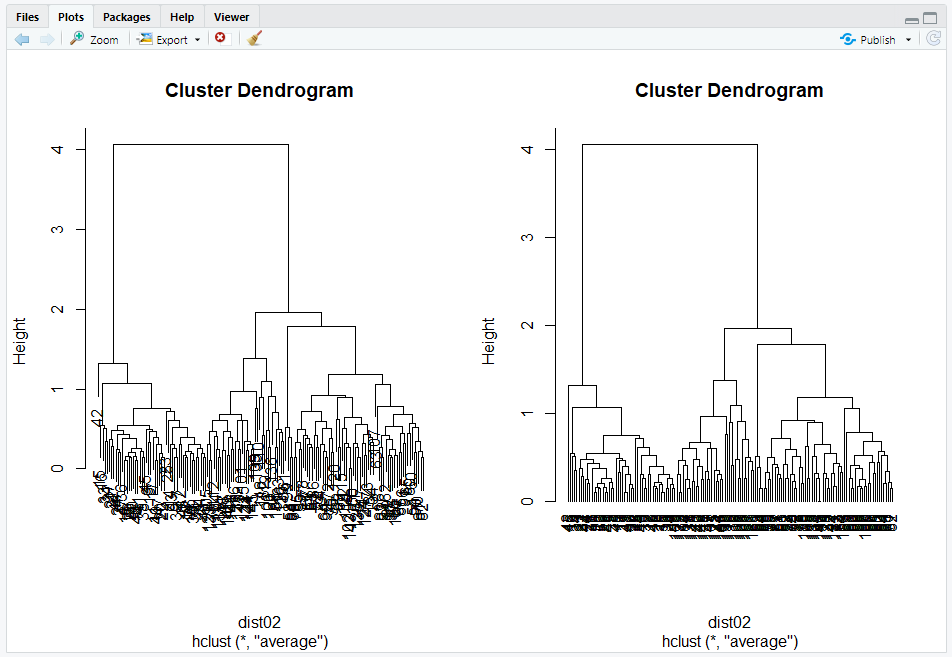
dist02 <- round(dist(iris[,1:4]),digits=3) # 소수7자리... 소수 2 자리
hc02 <- hclust(dist02, method="ave")
plot(hc02)
plot(hc02,hang=-1)
# (2.4) Kmeans----
iris01 <- iris
iris01$Species <- NULL
iris01
model_km <- kmeans(iris01,3)
model_km

table(iris$Species,model_km$cluster)

par(mfrow=c(1,2))
plot(iris$Sepal.Length,iris$Sepal.Width,col=iris$Species)
plot(iris$Sepal.Length,iris$Sepal.Width,col=model_km$cluster)

'R연습 200제 > 10_00. (R)통계적 분석기법1' 카테고리의 다른 글
| r_13_01. 통계적 분석 기법 (2) | 2024.08.31 |
|---|